
This post is about a really odd problem that occurred some while ago, and was solved with a really small configuration change on all vSwitches on all the hosts in the cluster. I haven’t come across the same problem on a single host, but that doesn’t say it’s not possible. As the topic says, the problem showed itself as just a really random packet loss between traffic from the Virtual Machine to the outside network. Sometimes it was just one out of 10 packets that got lost, at worst we lost 80% of the ICMP packets while testing.
Without doubt, this one was probably one of the most weird problems I’ve come across and it was really hard to pinpoint what the source of the problem was. At first we looked at our physical networking, making sure the ARP entries are shown correctly in the routers and switches all the way to verifying that all cables were set-up as they should be. Double checking everything and trying to test connections from as many sources as possible. We tried to question everything, even though it was proven to work after initially built. In the end we had to give up on that idea and conclude that no problem could be found. Initially we didn’t find any problems in the VMware environment either, as everything seemed to work as intended, except for unexplainable packet loss to virtual machines. Not even all of them!
To give a little background on the environment we have N amount of hosts in the cluster, with 2 network adapters on each of them dedicated for Virtual machine network traffic. These two network adapters are are connected to two different switches which are later down in the network connected together. This has has been configured to minimize downtime, and as such vSwitches see one network adapter as active and the other one in standby.
Testing…
With VMware vCloud we selected three types of networks to try things out with. One direct connection that exposed the Virtual machine directly to the outside network without any firewalls. The second network type was a virtual machine located behind a vShield firewall and last was virtual machines connected together with an internal switch but no outside connections. Testing was conducted by using basic ping and trace commands to verify routes and connectivity and in the case of the virtual machines behind the vShield firewall we tested both connections between the hosts as well as connections between the hosts and machines from external networks.
During this issue, we found that connections between external hosts and virtual machines with a direct connection always worked fine, as well as those that only had an internal connection. The machines we had packet loss with were only the ones that were behind a vShield firewall. To make matters worse, it wasn’t even all hosts behind a NAT connection. At first we thought it was an issue with vShield and replaced it with pFsense, unfortunately with no luck.
vSwitch “hidden” issue
As mentioned earlier, each of our hosts had two network adapters for virtual machine traffic. One NIC was configured as active and the second one as stand-by to allow fail-over switching. At this stage we had tried pretty much everything we could figure out and literally ran out of ideas. We got struck with good luck as we managed to catch the problem on the spot, while working and not working on one virtual machine only. The moment we realized what the main cause was when we moved one of the VM’s in a vAPP, connected to a vShield from one host to another. On the first host in the cluster it worked, but as soon as it was migrated to a second host, the packet loss started. Once moved back to the initial host, everything was fine again. No packets dropped and network connectivity worked as expected.
As long as all VM’s in a vAPP were on the same host, including the vShield firewall, everything worked. In case you run in to the same problem this is a crucial piece of information to verify to know if you are suffering from the same issue as we did.
The solution to the problem was to change the failover setting for each and single VSE-… dvSwitch (Distributed Virtual Switch) in the cluster! When you create a new vShield Edge in an organization, VMware also created a VSE-… named dvSwitch on the host. This dvSwitch has the same properties as another on the host, and thus also has the fail-over settings for the network cards. Check the settings of a few of them that work, and now open the properties of the network that doesn’t work. You will notice that the active and stand-by adapters are switched, meaning that if you have NIC#1 as the active adapter on VSE dvSwitch number 1 and NIC#2 as standby, and on the network that doesn’t work properly, these two network adapters will be switched so that NIC#2 is active and NIC#1 is as stand-by. Once you move these two network-adapters the same way, your network connection will work normally with no packet loss at all, even after moving a VM to another host.
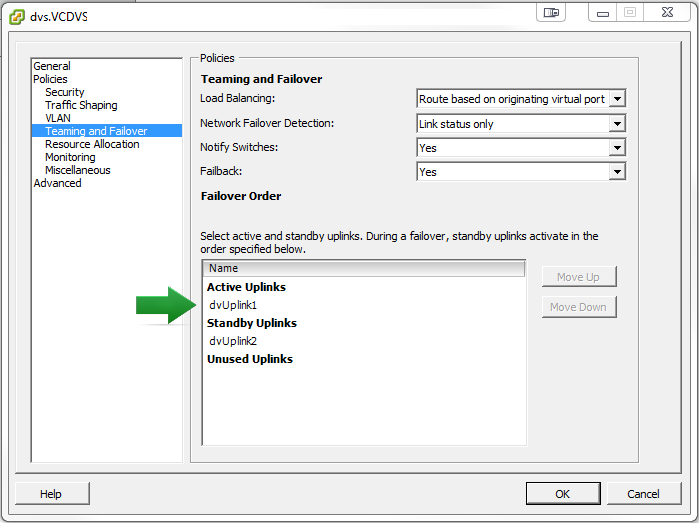
VMware support did mention that this order should not vary unless someone changes this manually. I would disagree with this, but haven’t been able to prove with any logs that it would change on it’s own. I have noticed that when creating new networks, the order might be revered and as such is incorrect from the start. I will get back to this once I have some more information.
The Reason
This can happen if any portgroup with running VM’s using VCNI (VCD Network Isolation backed) networks are configured to use more than one physical vmnic as dvSwitches only use one adapter to communicate over the physical network. If any dvSwitches have their network fail-over settings set incorrectly, the traffic will get mixed up and physical switches will send packets to the wrong vmnic on a host. And as such the packets will be dropped due to the nics being incorrect for that particular packet. When this happens, mac address tables will be flushed and started over and as such, allow some packets to get trough until another VM sends information on another dvSwitch and thus yet again break the mac address table and cause packet loss.
This is a vicious circle that will continue until ALL Distributed Virtual Switches are configured the same way!
VXLANs
This time there are some additional options to fix the problem, and they are named VXLANs. When using VXLANs it’s possible to have two (or more) vmnics enabled at the same time, thus making this problem obsolete. There are some additional reasons on why to use VXLAN’s, which can be found on VMware official site.
http://www.vmware.com/solutions/datacenter/vxlan.html
Thank you for this excellent post – you saved us a great deal of time and effort!
We had the exact same problem – intermittent connectivity from the VMs through VSE to external. What threw us at first was that we could ping the VSE from the VMs so all looked well; until we realised that pings from VSE back to the VMs were failing intermittently. Then some Googling got us here :)
We are still trying to get VMware to confirm to us exactly how the portgroup teaming would have got in this state in the first place, we have many other organisations running on this environment and they are all configured correctly…
Hope you get the issue fixed. If there is any information that would be of value from your VMware ticket, don’t hesitate to send me an e-mail and I will update this post.
THANKS!!!
We were seeing the same thing while using VXLANs, due to the same failover options being configured – No Etherchannel available to us as we’re not a Cisco-house. Setting the same order resolved the problem, many many thanks.